1. Samenvoegen Stambomen
Noodzaak voor de volgende stap
De reden voor de eerste stap is om dieren met onbekende ouders te herleiden. Als alle ouders bekend zijn, zijn alle dieren terug te leiden tot de oorspronkelijke founders (zie Stap 2). Als niet alle gegevens gekoppeld zijn en er dus gaten in de stamboom zijn ,an dat negatief uitpakken voor diversiteit en dus voor de gezondheid.
Regionale populaties
Is het mogelijk om een populatie op regionaal niveau te behouden? Natuurlijk is het mogelijk om de volgende stappen toe te passen op stambomen van slechts één land (vaak gedaan bij huisdierrassen) of een continent (vaak gedaan in programma's voor het behoud van soorten, zoals EEP in dierentuinen). Het resultaat van deze inspanning voor het behoud van de gehele populatie, ras of soort, is echter onzeker. Het zou heel goed kunnen dat de dieren die in stap 3 als genetisch belangrijk worden geïdentificeerd, in werkelijkheid al oververtegenwoordigd zijn, hetgeen enkel duidelijk wordt wanneer de wereldpopulatie zou worden geanalyseerd. Of erger nog, dieren die niet zo belangrijk lijken te zijn en vergeten worden, maar dat in feite wél zijn zodra de hele populatie wordt geanalyseerd.
Analyse op basis van onvolledige stambomen
Als de analyse gebaseerd is op verwantschap berekend voor 7, 8 of 9 generaties, bleek uit onderzoek dat er geen significant verschil was. Dit leidde tot de wijdverbreide misvatting dat niet alle generaties nodig zijn om verwantschap te berekenen. Toen de verwantschap echter tot aan de founders werd berekend en dus alle generaties betrokken waren, bleek uit onderzoek dat de analyse drastisch veranderde. Onderstaande figuur illustreert dit verschil. Clusteranalyse is twee keer uitgevoerd op dezelfde populaties. Het verschil tussen de twee analyses is overduidelijk groot, evenals de negatieve gevolgen voor acties die zouden volgen op onvolledige berekeningen.
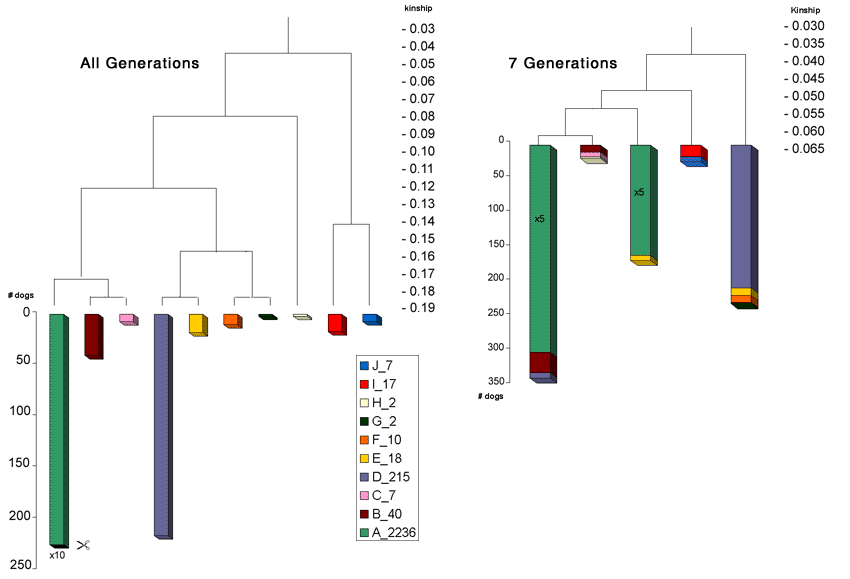
Het belangrijkste om op te merken: met een onvolledige dataset, het plaatje ziet er totaal anders uit.