1. Merge Pedigrees
Necessity for the next step
The reason for the first step is to avoid animals with unknown parents. If all parents are known all pedigrees will end up into the original founder individuals (see Step 2 ). If data is not connected there will be gaps in the pedigree with a dramatic result for diversity.
Regional populations
Is it possible to preserve a population on regional level? Of course it is possible to apply the next steps on pedigrees of only one country (often done in domestic breeds) or a continent (often done in species conservation programs, like EEP in zoos). The result of this effort towards conservation of the entire population, either breed or species, however is uncertain. It might very well be that the animals that show as genetically important in step 3 are actually abundant when the global population would be analyses. Or worse, animals that do not show as important, actually are the ones that can save the population if the entire population would have been analysed.
Analysis based on incomplete pedigrees
When analysis is based on kinship calculated for 7, 8 or 9 generations, research showed that there was no significant difference. This led to the widespread misapprehension that not all generations are needed to calculate kinship. When kinship was calculated up to the founders, however and therefore all generations were involved, research showed that analysis changed dramatically. The figure below illustrates this difference. Cluster analysis was performed two times on the same populations. There is no need for details here, but the difference between the two analyses is clear. The whole research can be found here.
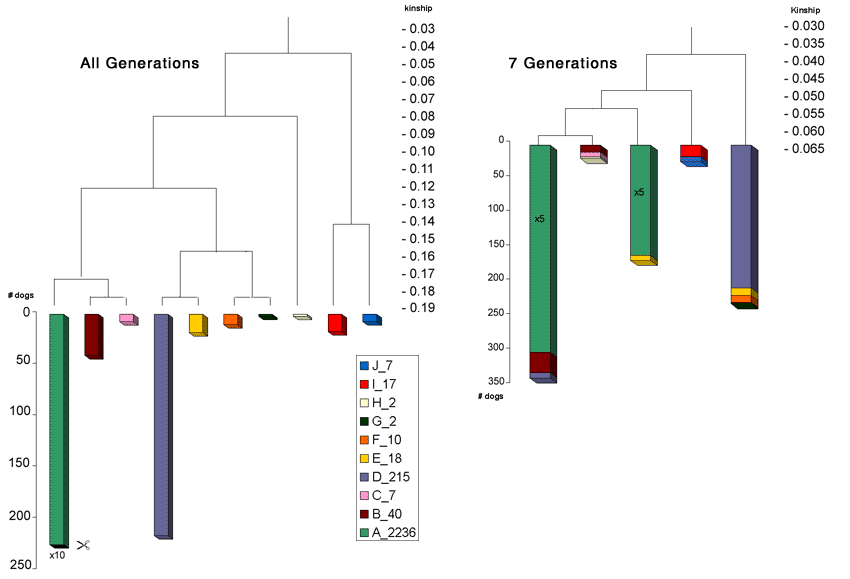
The most important thing to notice: with an incomplete dataset, the ‘image’ looks completely different.